01
Introduction
產品介紹
DataStudio 自動根據您的標籤資料,在大量資料表中找尋有用的特徵,加速資料分析的流程,減少專案的人力配置
在一個分析案中,定義好分析問題之後,經常需要花費分析師們大量的時間來進行資料收集 & 整理。尤其在國泰這樣資料量豐富且龐大的環境中,快速的資料收集就顯得更為重要。 DataStudio 能根據使用者定義好的 Label Table,快速的從指定的資料庫中找出最適合本次建模分析的特徵, 讓分析師們能有更多的時間與業務單位溝通、了解需求。
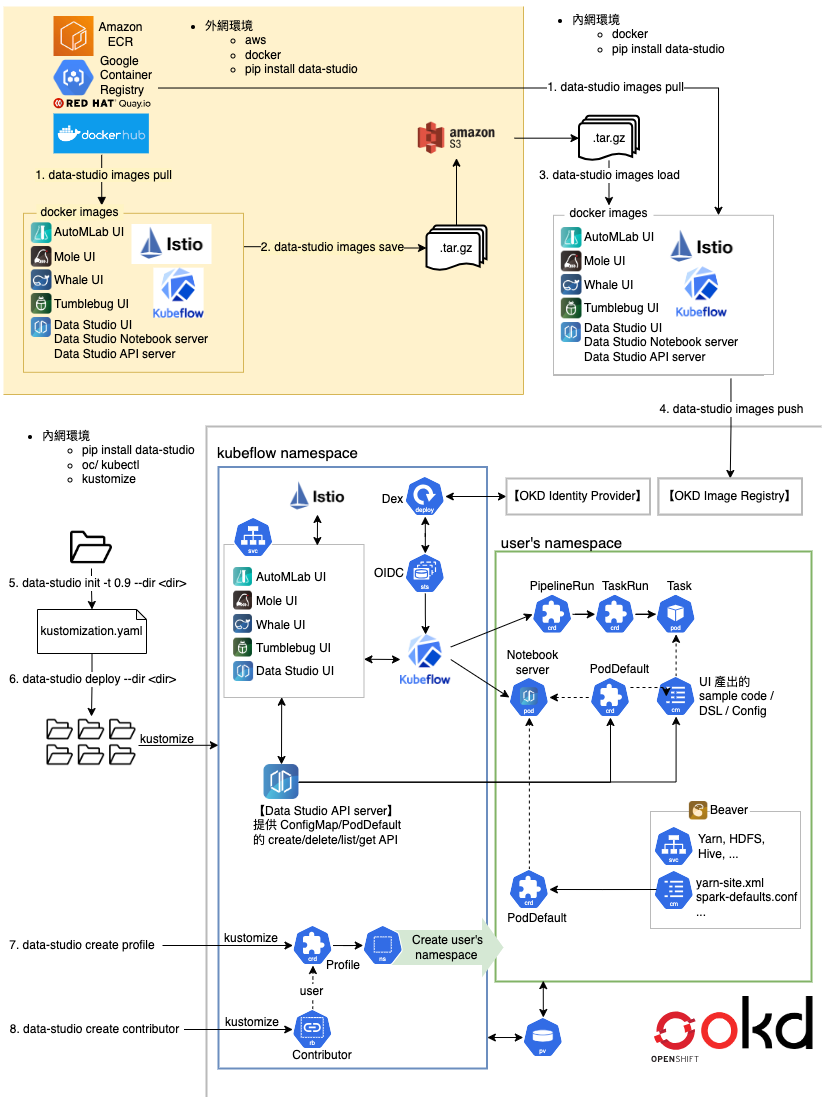
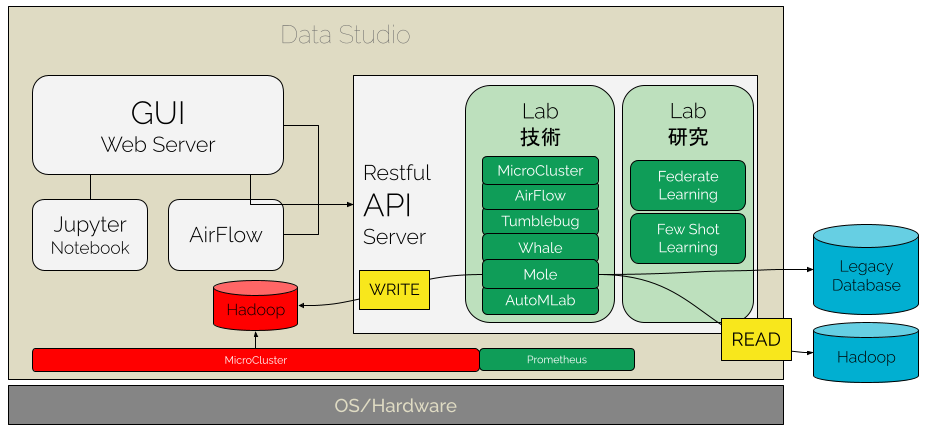
完整 DataStudio 流程圖
DataStudio 運用了 Spark 技術,在資料海中,先計算了許多統計指標,加速接續的特徵重要度計算。有趣的是,這些統計指標是可以共享的,在各個專案中互相參照,省下更多時間。
如果您好奇 DataStudio 的特徵重要度的演算法,歡迎參照我們的使用者文件喔!